non-local block 计算消耗较大,这篇论文提出了 Interlaced Sparse Self-Attention,包括一个 long-range attention 和一个 short-range attention,用两个稀疏的相似矩阵代替了原来 self-attention 中密集的相似矩阵,减小了普通的 self-attention 的计算量。
Method
Interlaced Sparse Self-Attention
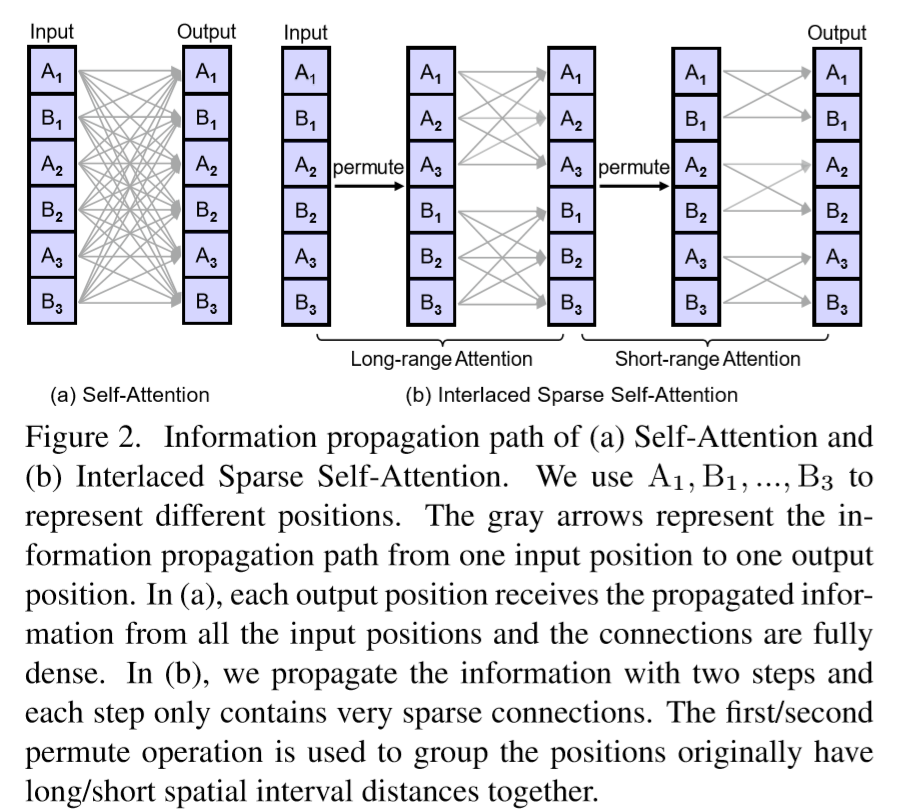
ISA 处理一维输入的信息传递播示意图如上图所示。首先将输入特征图的位置(像素)均分为 Q 个子块,每个子块由 P 个位置组成。对于 long-range attention,我们从每一个子块中采集一个位置来构成 P 个包含 Q 个位置的子块,每个构造子集中的位置均具有较长的空间间隔距离。在每个构造子块上应用普通的 self-attention 来计算稀疏块相似矩阵 ,根据 在每个子块间传播远距离信息。对于 short-range attention,直接在原始 Q 个子块上应用普通的 self-attention 来计算稀疏块相似矩阵 ,根据 在临近位置之间传播信息。最后结合两个 attention 模块,就可以将信息从输入的每个位置传递到输出的每个位置。
Model
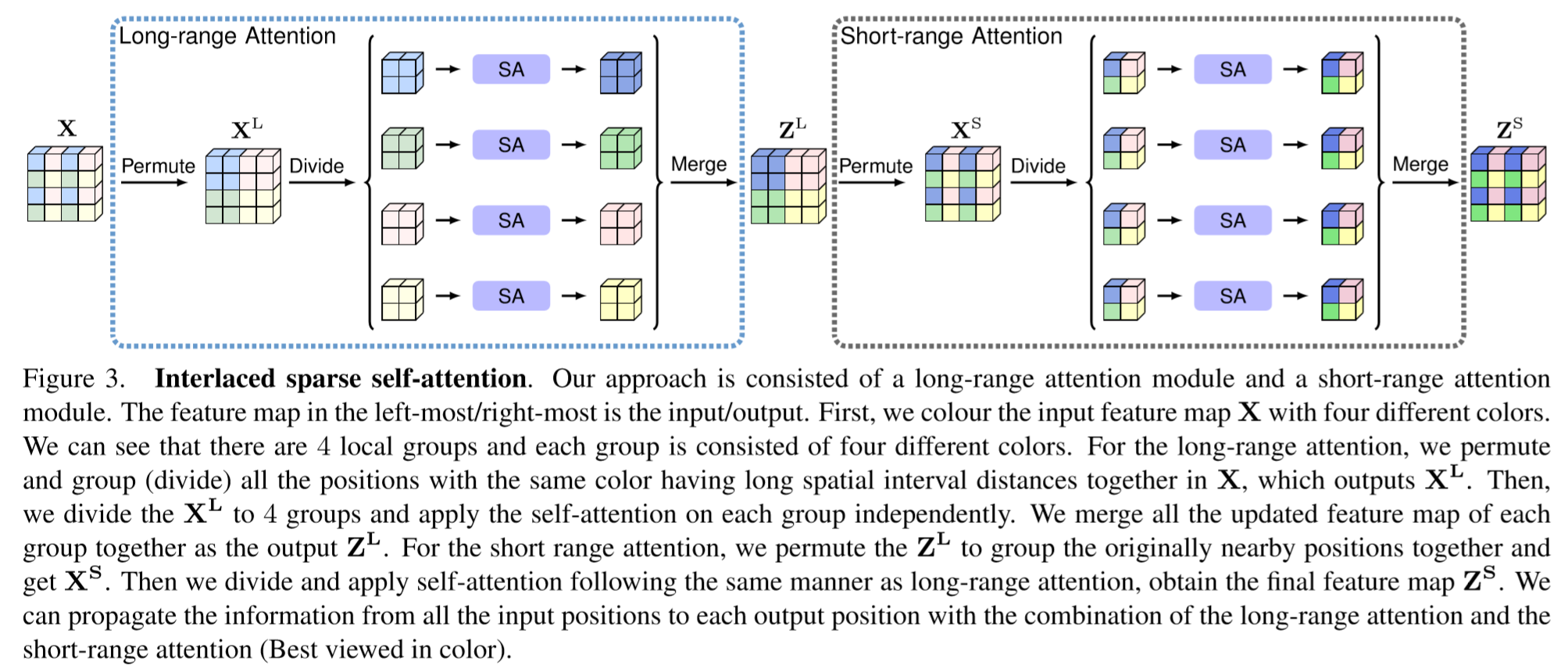
ISA 模型示意图如上图所示,其 python 代码如下:

计算量:

当 时计算量最小。
Experiment
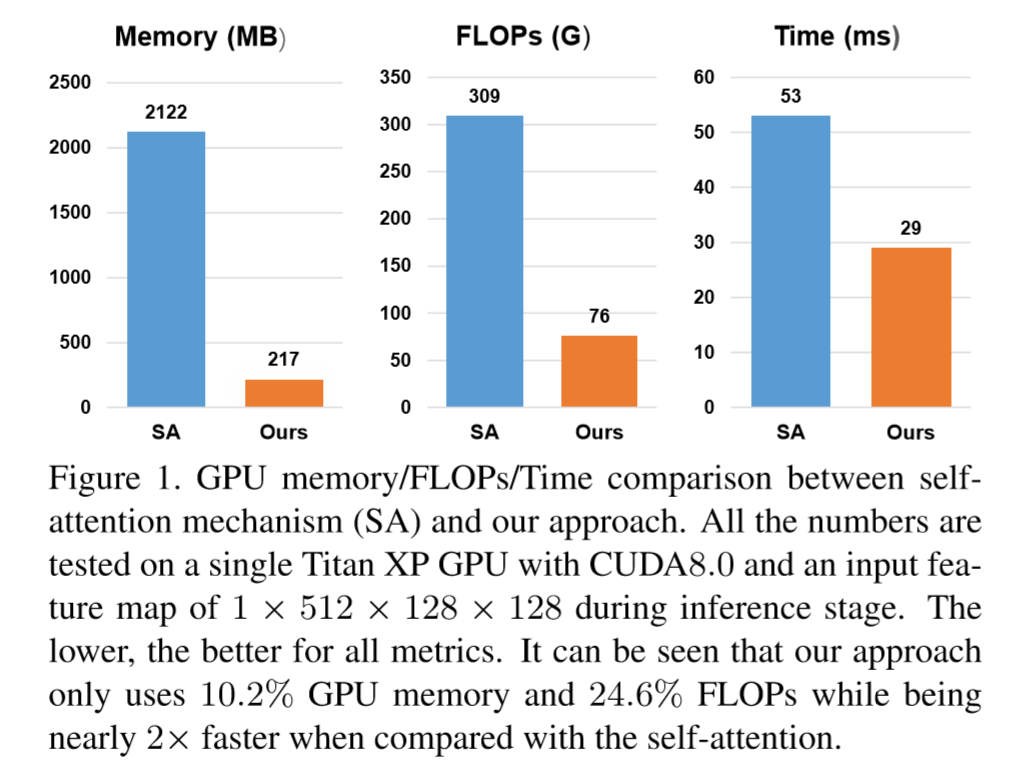
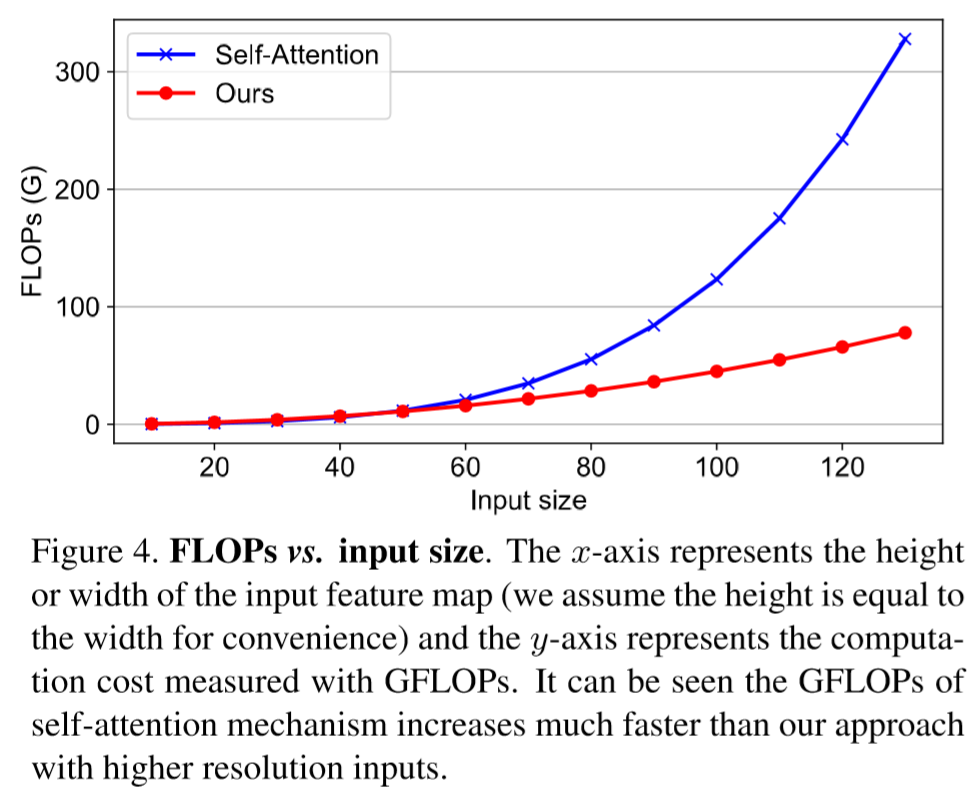
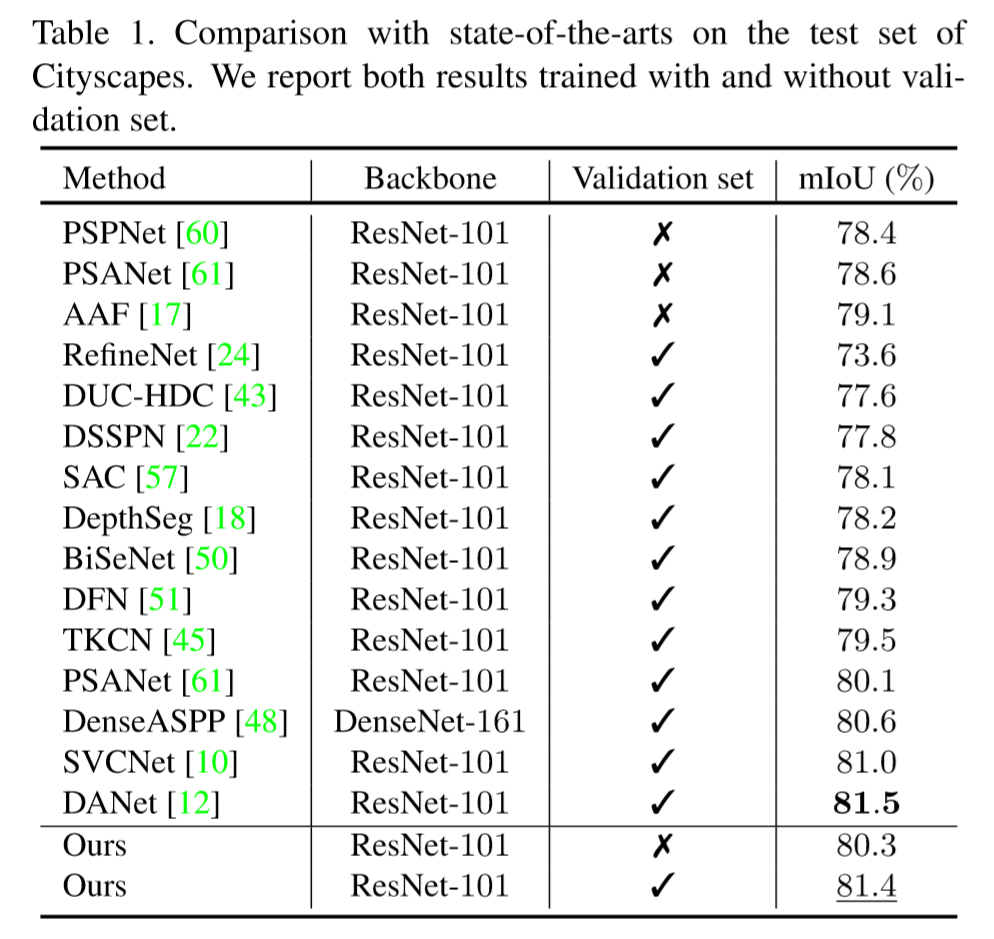
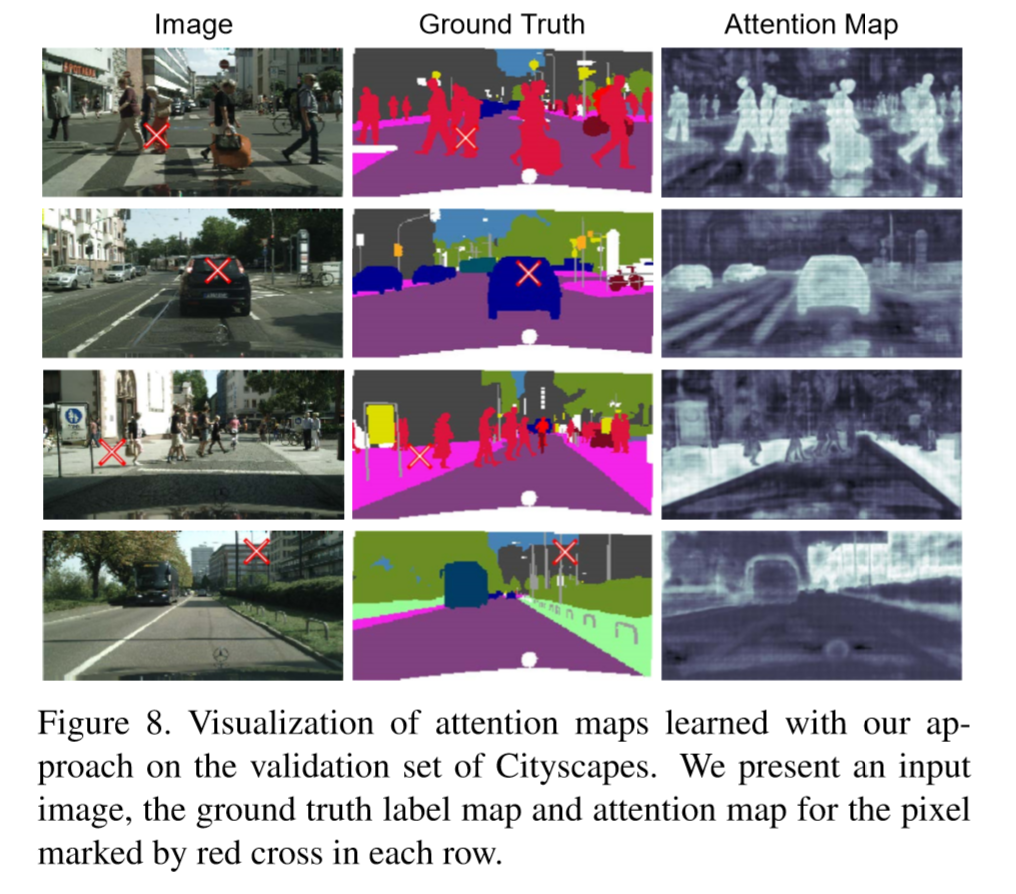
-
Previous
FastFCN: Rethinking Dilated Convolution in the Backbone for Semantic Segmentation -
Next
Pytorch并行训练