空洞卷积能获得更大的感受野同时不减小特征图分辨率,提高语义分割精确度,但是空洞卷积输出分辨率变大,极大的增加了计算开销,因此 FastFCN 提出了 Joint Pyramid Upsampling(JPU) 来提取高分辨率特征图。
Method
Joint Upsampling
作者从 Joint Upsampling 出发,给一个低分辨率的目标图像和高分辨率的指导图像,joint upsampling 目的是通过细节和结构的转换从指导图像得到高分辨率的目标图像。低分辨率的目标图像 由低分辨率的指导图像 经 转换得到: 。我们希望得到一个转换 近似 并且计算复杂度更小,然后高分辨率的目标图像 就由高分辨率指导图像通过 转换得到: 。joint upsampling的定义为:

Reformulating into Joint Upsampling
在空洞卷积网络 DilatedFCN 中,一般将输入先经过普通卷积网络,然后用一系列空洞卷积处理,与 DilatedFCN 不同的是,作者先用一个步长 s=2 的卷积,然后再应用步长 s=1 的普通卷积。
作者将空洞卷积分解为 Split、Conv、Merge 三个阶段,将 s=2 的 StrideConv 分解为 s=1 的普通 Conv 和 Reduce 两步,如下图所示:
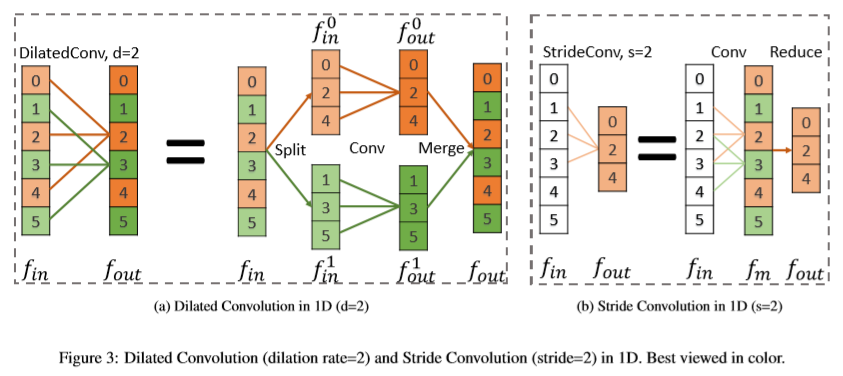
于是两个过程如下公式得到:
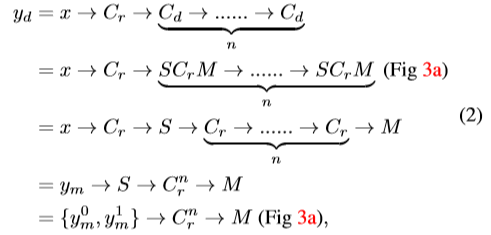
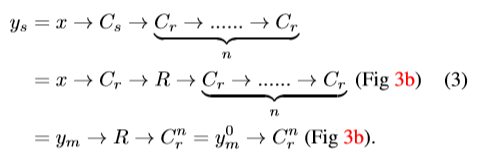
其中 代表 regular/dilated/stride 三种 conv, 代表 n 层 regular conv,S,M,R 代表 split,merge,reduce 三种操作。
因此,空洞卷积输出 的近似值 y 可由如下公式得到:
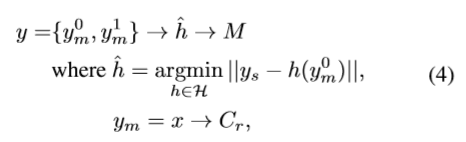
这与 joint upsampling 的定义相同。
Model
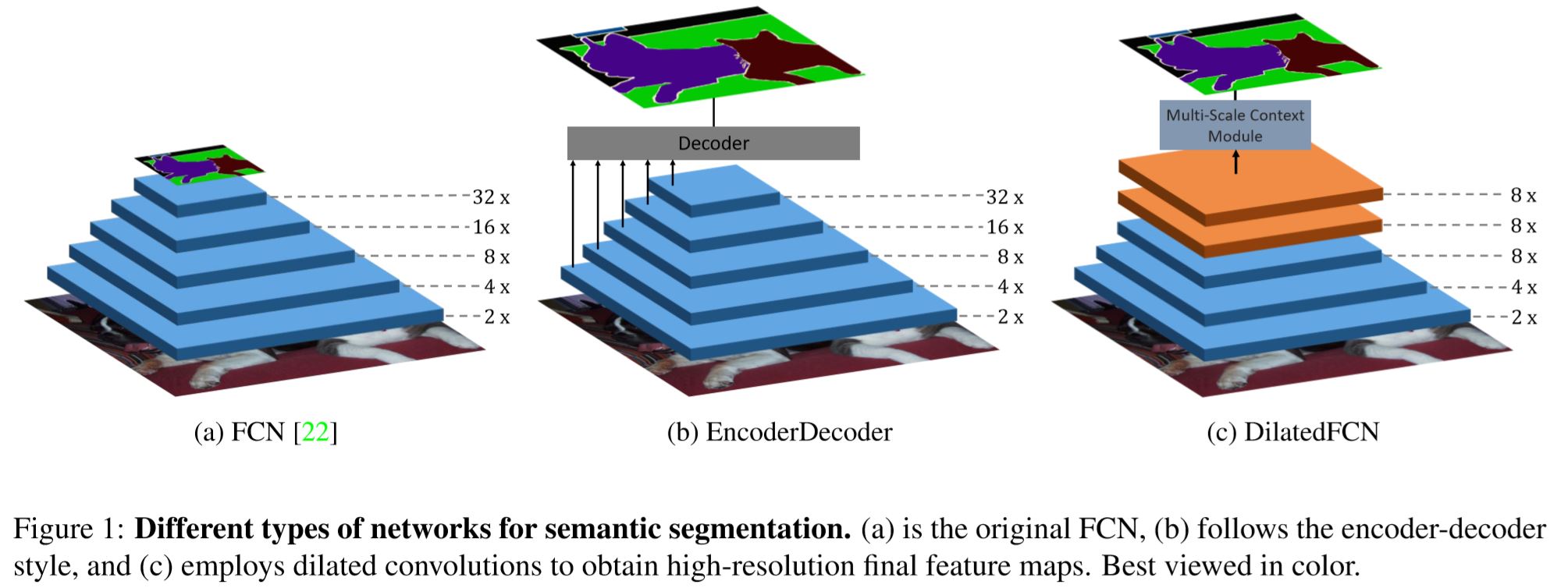
上图分别是 FCN、编码解码结构和应用了空洞卷积的 FCN(DilatedFCN)
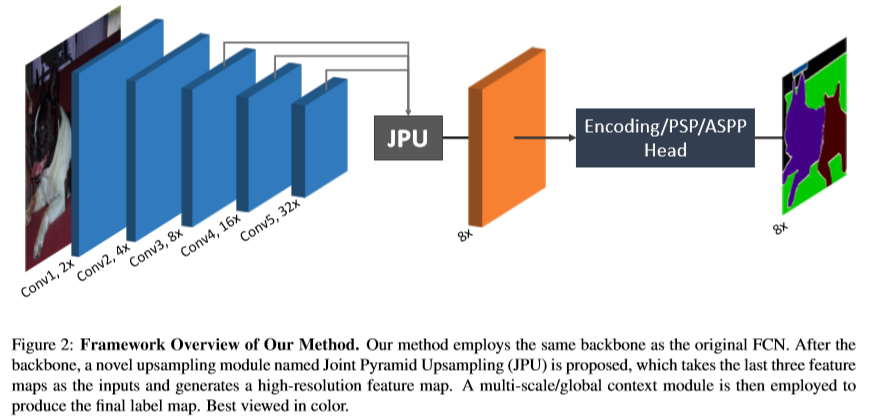
FastFCN 的结构如上图所示,与 DilatedFCN 不同的是,恢复了最后两层 conv4 和 conv5 的普通卷积,然后将 conv3、conv4 和 conv5 的输出都输入到 JPU 模块,JPU 的输出与 DilatedFCN 一样 output stride 为 8,再经过一个编码器或者 PSP 或者 ASPP 后得到输出。
JPU 模块如下图所示:
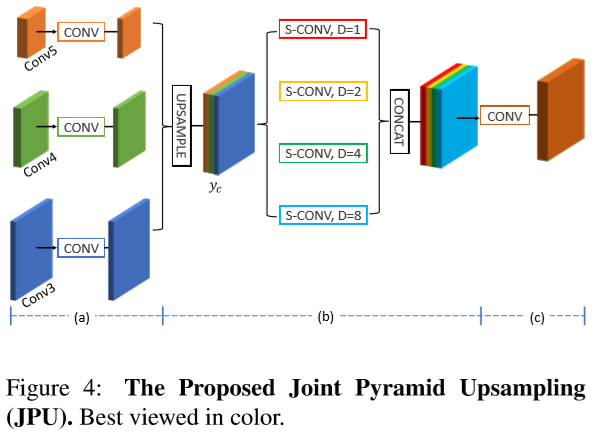
S-CONV 为深度可分离卷积,D 为空洞卷积率。
具体的,conv3、conv4、conv5 的输出先分别经过一个 regular conv block,这样做的目的是:1、得到 ;2、将输入转换成少且相同的通道数。然后 conv4 和 conv5 的输出经过 upsampling 后与 conv3 的输出 concat 到一起,输入到四个具有不同空洞卷积率(1,2,4,8)的平行的可分离卷积中。
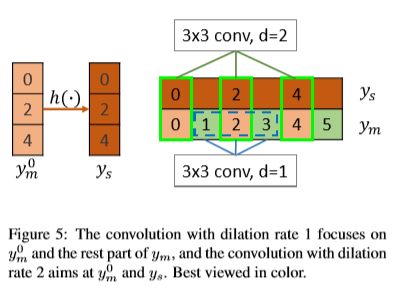
不同的空洞卷积率具有不同的作用。d=1 用于捕捉 和 剩余其他部分之间的关系(如图5中蓝色虚线框所示),d=2,4,8 用于学习将 转换为 的映射图 (如图5中绿色框所示)。因此 JPU 模块能够从多级特征图中提取多尺度上下文信息,而 ASPP 模块只能从最后一层特征图中提取信息,这是 JPU 与 ASPP 重要的不同。
Experiment
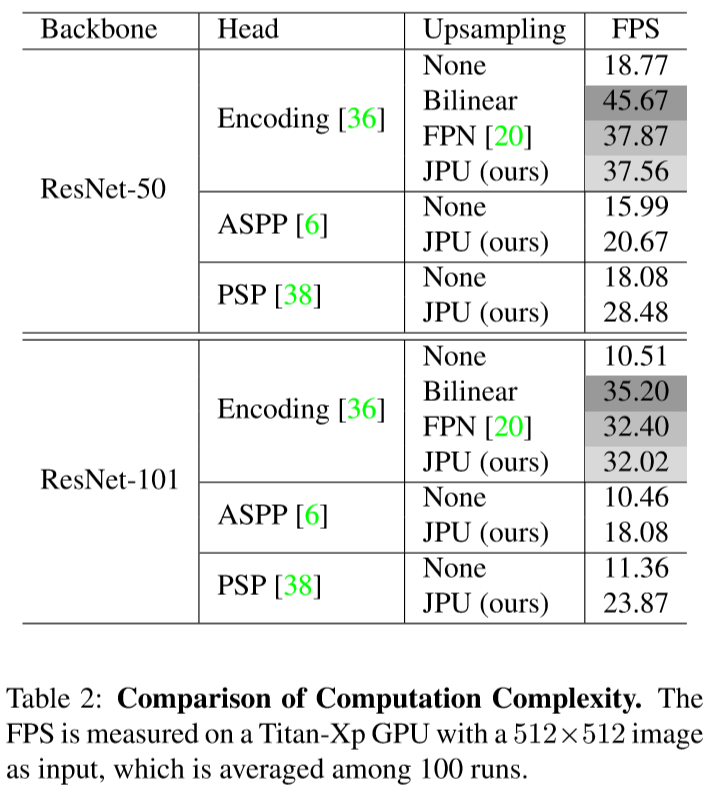
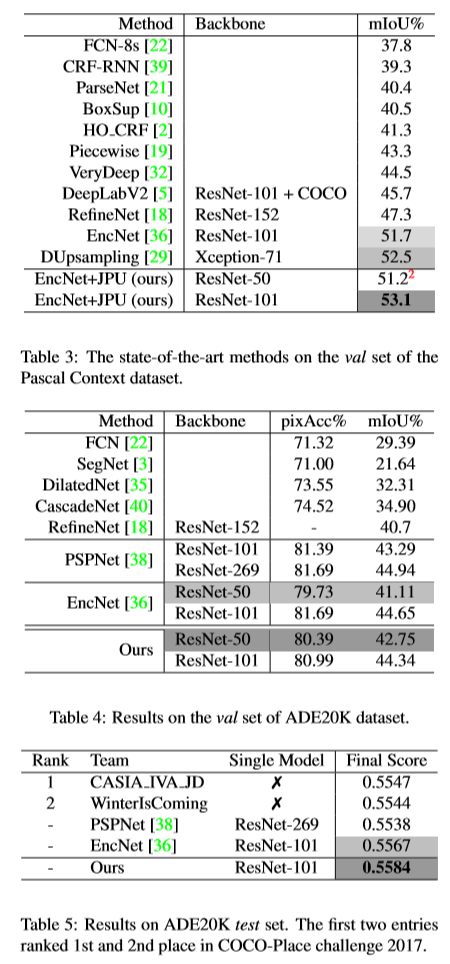

-
Previous
CCNet: Criss-Cross Attention for Semantic Segmentation -
Next
Interlaced Sparse Self-Attention for Semantic Segmentation