长距离依赖能捕捉有用的上下文信息有利于视觉的理解,这篇论文作者提出了一个 Criss-Cross Network (CCNet) 能有效同时很高效地得到这种重要的信息。相比 non-local block 节省了 11 倍的 GPU 使用率和 85% 的 FLOPs(每秒浮点计算次数),并且在多个语义分割数据集上达到了 state-of-the-art。 论文链接
Method
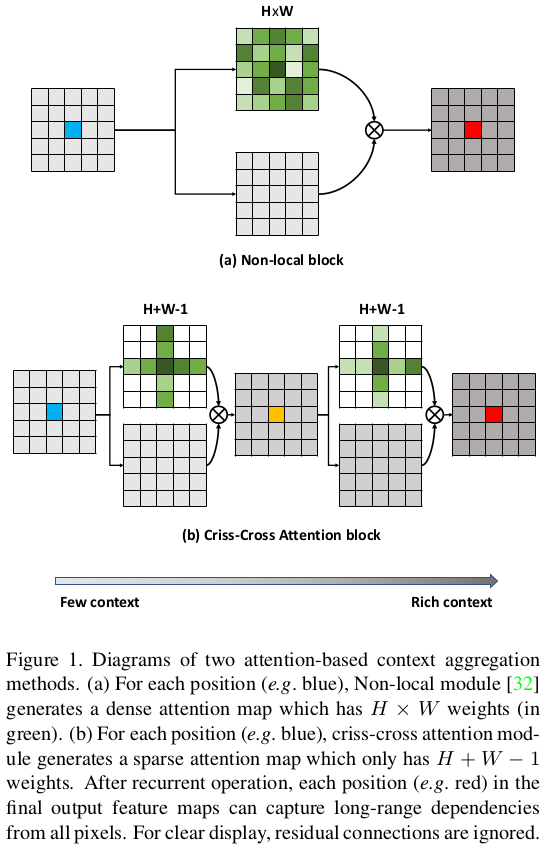
上图第一行就是 non-local block 大致的过程,他的时间和空间复杂度都是 ,H 和 W 是特征图的尺寸,一般语义分割模型为了获得精细的结果特征图分辨率都比较高,所以使用 non-local block 的计算量特别大。
作者呢就提出如上图第二行所示的 criss-cross(十字交叉) 操作,每个点不再与所有点相关联,而是只与同一行和同一列的 H+W-1 个点相关联。通过连续的两个 criss-cross 操作就可以捕捉到全局的上下文信息。而时间和空间复杂度减少为 。
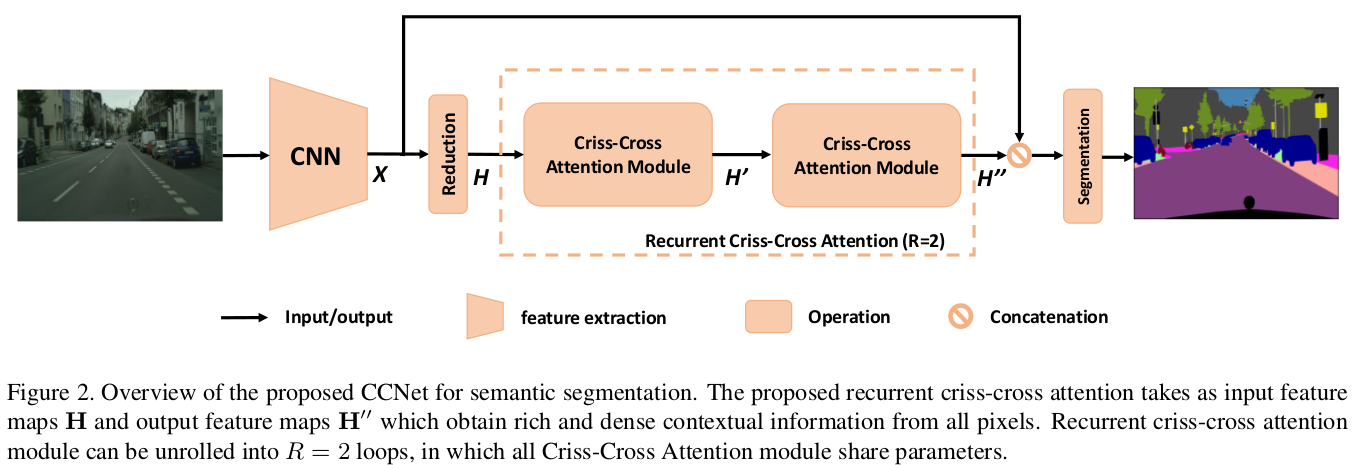
CCNet 整体结构就如下图所示,经过一个 DCNN 提取出特征 X ,经过一个卷积减少通道数后得到 H,在经过连续两个 criss-cross attention(CCA) module 得到 ,最后与 X concate在一起形成 skip-connect 结构。
下面具体来看看 criss-cross attention(CCA) module,如下图所示:
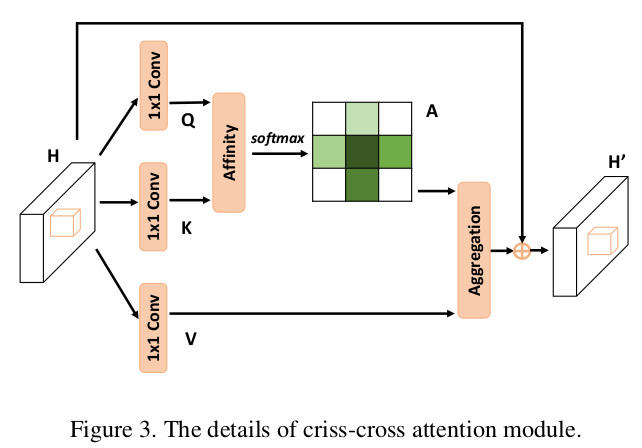
首先,和 non-local block 操作一样,输入特征 H 先经过两个 1*1 的卷积得到两个特征图 Q 和 K。然后 Q 和 K 通过一个 Affinity 操作后得到一个 attention map 。
具体的,Q 和 K 的维度为 ,
对于 Q 空间维度的每个位置 u,我们能得到一个向量 : ,
另外,在 K 的相同位置 u 的同一行同一列上我们能得到 H+W-1 个点的特征集合: ,
为 的第 i 个元素。
Affinity 操作定义为: ,
定义了特征 和 之间的相关程度, 。
然后我们在 D 的通道维度上应用 softmax 就得到了 attention map A 。
第二步,特征图 H 经过第三个 1*1 卷积进行特征 adaption 得到 ,
和刚刚操作类似,对 V 空间维度上每个位置 u,得到一个向量 和与 u 同行同列的点的集合 ,
我们通过 the Aggregation operation 来捕捉长距离上下文信息:
表示输出特征图 上位置 u 的特征向量, 是 A 上位置为 u,通道数为 i 处的值。加上输入的特征 H 来加强局部特征和增加逐像素表示就得到最后输出 。
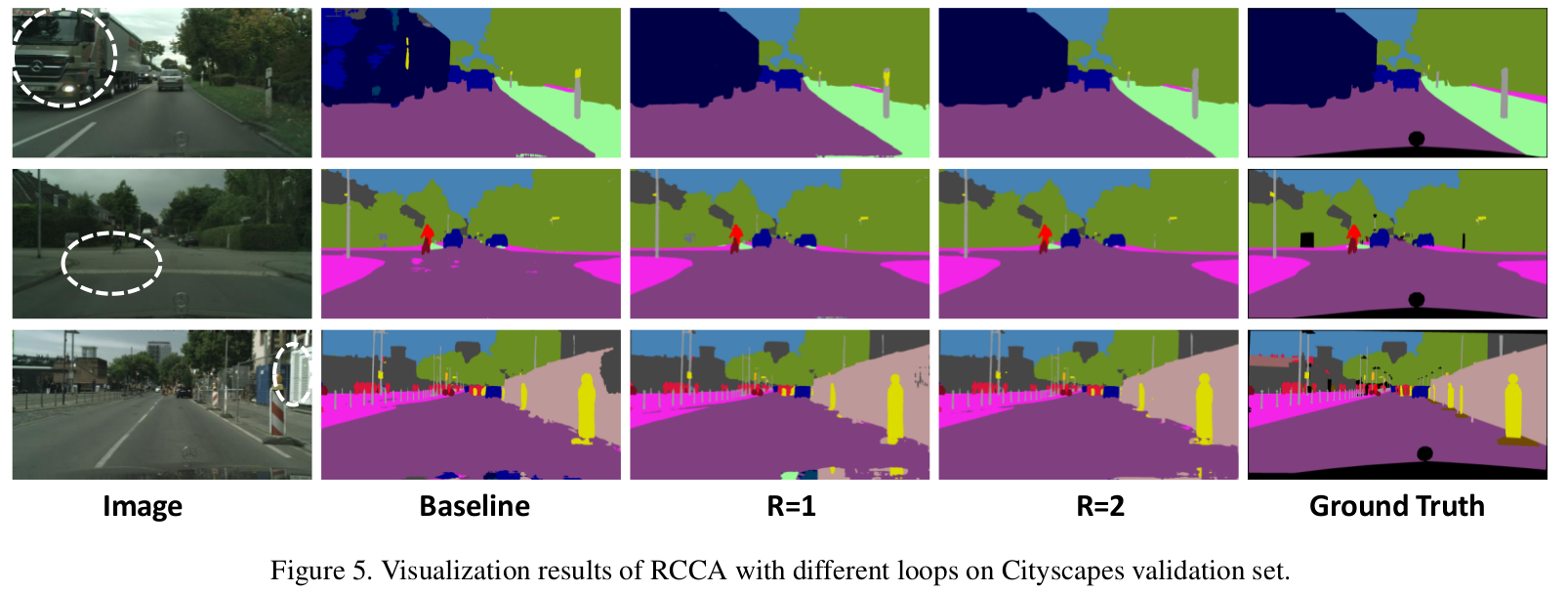
一个 criss-cross attention module 只是像素点与全局的稀疏连接,为了获得密集连接,作者提出了 recurrent criss-cross attention(RCCA) module,就是重复使用 criss-cross attention module,事实上,当 Loop=2 ,也就是重复两次就能捕捉到来自所有像素点的长距离依赖,生成的特征图因此具有密集而丰富的上下文信息。RCCA module 中重复的 criss-cross attention module 是共享参数的,所以是不会增加额外参数的。下图展示了空间维度上下文信息传播路径:
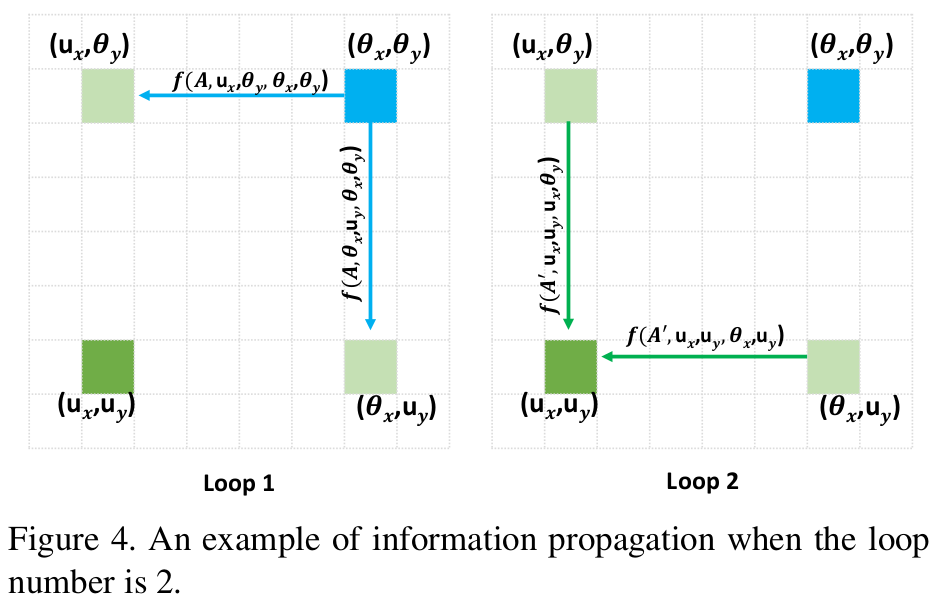
Loop 1 时 处的信息传递给了他周围的点 和 ,到 Loop 2 时, 会接收 和 上的信息,此时 的信息就传播到了 。这样信息不断传递开来,每个点就会接收到全部像素点的信息。
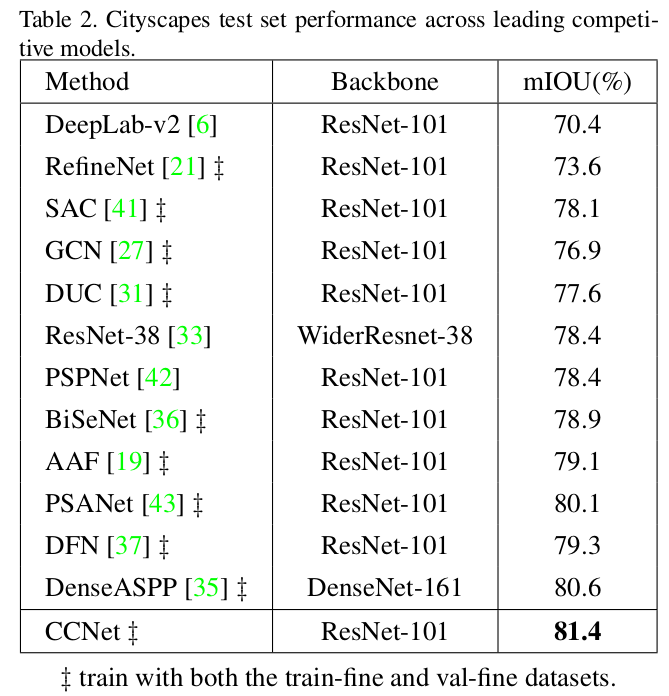
Experiment

-
Previous
MobileNet -
Next
FastFCN: Rethinking Dilated Convolution in the Backbone for Semantic Segmentation