在使用 Pytorch 的 torch.nn.DataParallel() 训练网络时发现第一块显卡显存占用非常大,其他显卡显存占用比较小,出现了 GPU 负载不均衡的问题,于是换用 torch.nn.parallel.DistributedDataParallel(),可以更均匀的分配 GPU 资源。
Method
torch.nn.parallel.DistributedDataParallel() 在使用时分为单机多卡和多机多卡,我只使用了单机多卡的情况。
单机多卡设置步骤
-
1 2 3 4
#设置参数 parser = argparse.ArgumentParser() parser.add_argument('--local_rank', type=int, default=0) args = parser.parse_args(params)
-
1 2 3 4 5
torch.cuda.set_device(args.local_rank) #初始化 torch.distributed.init_process_group(backend="nccl") # 必须先将model加载到GPU再使用DistributedDataParallel,设置find_unused_parameters=True否则报错 model = torch.nn.parallel.DistributedDataParallel(model.cuda(),find_unused_parameters=True)
-
1 2 3 4 5 6
#编写Dataset加载数据集 dataset = Tusimple(path, mode, transform) #使用DistributedSampler去share数据 dataset_sampler = torch.utils.data.distributed.DistributedSampler(dataset) #使用DataLoader时设置sampler,设置pin_memory=True可以更快,也可以不用 dataset_loader = DataLoader(dataset=dataset,shuffle=shuffle,batch_size=batch_size,num_workers=num_workers, pin_memory=True,sampler=dataset_sampler)
-
必须使用python -m torch.distributed.launch运行程序,torch.distributed.launch会给程序传递local_rank参数,所以在第一步要设置,运行命令:
CUDA_VISIBLE_DEVICES=’0,1,2,3’ python -m torch.distributed.launch train.py
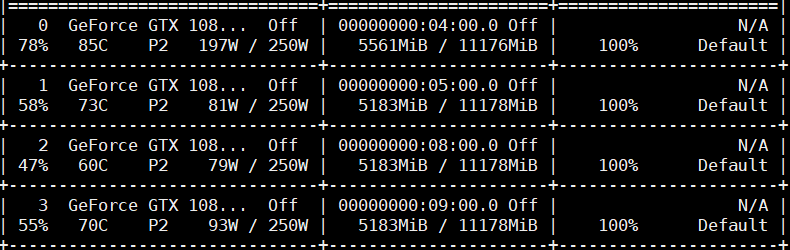
运行时 GPU 占用如下,可以看到显存分配比较均匀。
-
Previous
Interlaced Sparse Self-Attention for Semantic Segmentation -
Next
Multi-lane Detection Using Instance Segmentation and Attentive Voting